Effective editing of personal content holds a pivotal role in enabling individuals to express their creativity, weaving captivating narratives within their visual stories, and elevate the overall quality and impact of their visual content.
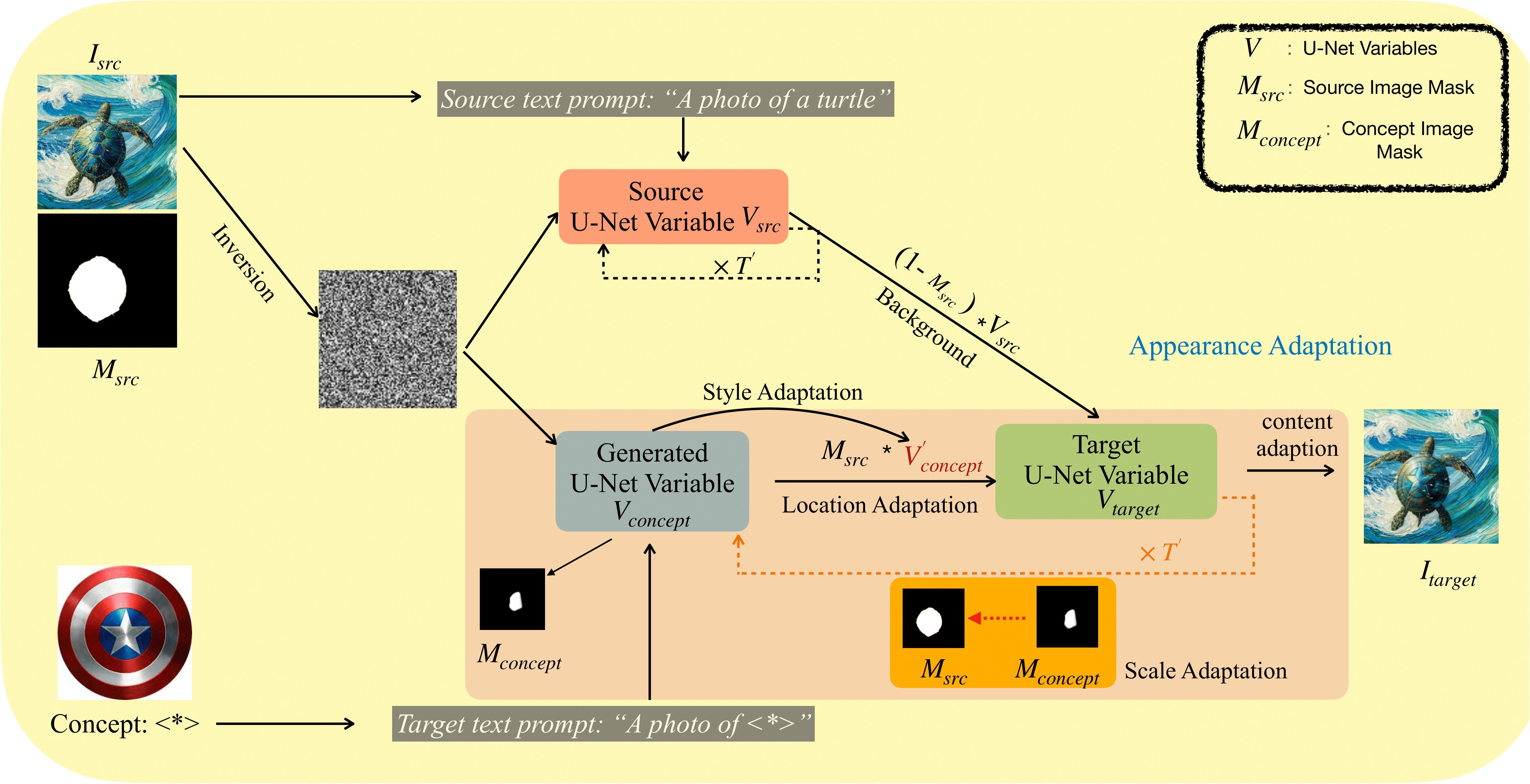
Therefore, in this work, we introduce SwapAnything, a novel framework that can swap any objects in an image with personalized concepts given by the reference, while keeping the context unchanged.
Compared with existing methods for personalized subject swapping, SwapAnything has three unique advantages: (1) precise control of arbitrary objects and parts rather than the main subject, (2) more faithful preservation of context pixels, (3) better adaptation of the personalized concept to the image.
First, we propose targeted variable swapping to apply region control over latent feature maps and swap masked variables for faithful context preservation and initial semantic concept swapping. Then, we introduce appearance adaptation, to seamlessly adapt the semantic concept into the original image in terms of target location, shape, style, and content during the image generation process.
Extensive results on both human and automatic evaluation demonstrate significant improvements of our approach over baseline methods on personalized swapping.
Furthermore, SwapAnything shows its precise and faithful swapping abilities across single object, multiple objects, partial object, and cross-domain swapping tasks.